What Is the Perfect Training Plan?
When we look at training, what really differentiates a successful training block from an unsuccessful one? Did we improve a performance marker like FTP, did we achieve the Zwift race performance we’d been dreaming about?
And what are the most important variables in our training?
- One is certainly the makeup of our actual training. This can include the number of training hours and rest days, whether we followed a threshold or polarized approach, how the intervals are structured, strength training routines, and so on. These variables alone already lead to a huge amount of possibilities in organizing our training. (For example, Zwift’s own workout library has more than 1000 workouts to choose from.)
- Secondly, sleep and stress can be considered. If our body is stressed from training, work, or personal life, this can certainly influence our readiness to train. Similarly, attempting a hard workout after a night of terrible sleep is often counterproductive.
- Thirdly, nutrition is definitely important. Most of us need to fuel properly and subscribe to a generally healthy diet in order to let our bodies adapt to training.

A perfect training plan combines these three areas into a formula that leads to a successful outcome for the athlete. And it does so in a personalized way. Should we expect there to be a simple or intuitive mathematical equation that works for everyone and tells us, “If you do a certain training input, this will be the outcome”? Most likely not. Human beings are complex and their response to training is individual, which you know if you’ve ever tried to copy the training plan of the superstar on your local group ride and felt like you were going to burn out in a week.
This makes finding a training plan a perfect problem for artificial intelligence (AI) and in particular machine learning. We also need plenty of good-quality data. Let’s examine this for three important areas of training:
- Training data: check. Our power meters, smart trainers, watches, heart rate monitors, etc. are tracking our training pretty much every second and have seen widespread use for years. Furthermore, Zwift, Garmin, Strava etc. make the data available to export, import, and share.
- Sleep and stress: getting there. There has definitely been some progress tracking recovery, sleep, and stress, such as via heart rate variability (HRV) or questionnaires that you have to fill out.
- Nutrition: difficult but we’ll get there eventually. Probably very few people have the discipline to consistently fill out a questionnaire with exact quantities they eat on a daily basis, but this process will hopefully get to an acceptable level of automation eventually with improved image recognition, etc.
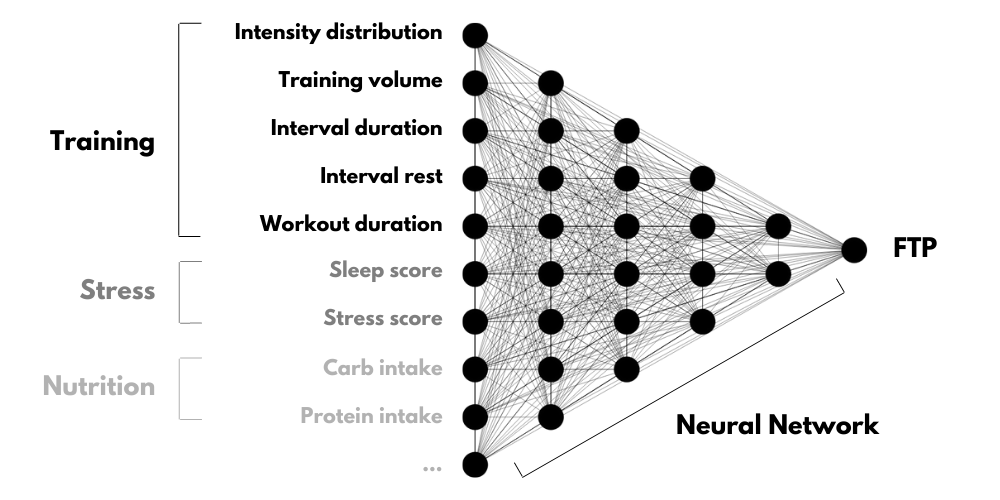
Right now, it is reasonable to expect to track someone’s training data over time and also their sleep and recovery metrics, albeit with less accuracy.
What can AI training do today?
There are two main areas where AI is being used in endurance training right now: adaptive training and predictive training based on training data and recovery and sleep data.
In adaptive AI training, you start with a one-size-fits-all training plan (for example a Zwift training plan) based on best practices for endurance athletes as a whole such as polarized training. Then you adapt someone’s plan in real-time based on their recovery metrics and/or performance in the plan.
For instance, such a plan might automatically replace a hard workout scheduled for the current day with an easy recovery workout if your sleep stress score from the night before is very high. In another case, the AI might realize that certain interval durations are too long for you to successfully complete the workout based on your past attempts and sprinkle in more rest intervals so you would be able to achieve the desired training load.
In predictive AI training, the idea is to start with a training plan that is tailored to the athlete right from the get-go. As such it cannot be downloaded from a training plan library but has to be created by the AI for each athlete individually. A machine learning model – a digital twin – is trained on the athlete’s historical training data to correlate training outcomes (FTP test results, race performances, etc.) with training inputs. The model is thereby able to become predictive. It can answer the question: If I do X training plan, what will be the result in a performance metric?
The model is individual to each athlete and can hence account for the fact that different training routines will have different results for different people, which is the central aspect of personalization. Predictiveness is a powerful feature. It can be used to find the optimal training plan outcome in the desired area of improvement (e.g. FTP) on a particular date. Apart from being outcome-optimized, the predictive training plan is based on what you have done historically, i.e. something you can reasonably expect to be able to maintain.
Today, the metrics that are predictive at the +/- 5% level are power for cycling, gradient averaged pace (GAP), and most likely power for running. Heart rate data is generally too dependent on external factors to be a good predictor of performance.
What will AI training be able to do in the future?
In the short term, the advancements in adaptive and predictive AI training will be increasingly combined. Starting with a predictive and personalized plan, the AI will make more and more fine-grained adjustments. This includes adjusting details of your training plan while collecting more information as you proceed through the plan and adjusting to unexpected events such as sickness, work stress, etc.
The training community will come up with more and more ways to make use of the data we already have, improve model architectures, fine-tune routines and parameters, cover more edge cases, etc. AI training is still a very new field and the underlying fields, including machine learning, are undergoing very rapid development and improvement themselves.
Improved tracking of the athlete’s fitness state, such as non-invasively tracking athletes’ ventilatory thresholds via HRV data, are exciting prospects for predictive AI training. They can improve prediction errors and shorten feedback loops and ensure that training zones are set correctly and checked regularly.
In the mid to long-term future, fully capturing all relevant training metrics including nutrition is possible. It is easy to imagine other physiological or metabolic metrics – maybe some we are not even thinking about yet – becoming more widespread and accessible, providing additional valuable data inputs.
Other questions might be asked of our digital twins such as improved real-time advice on our pacing or race strategies that are based on algorithms processing information in real-time on our wearable devices, including our metabolic state, course profile, weather, and others. Form tracking devices can provide data to predict and reduce injuries and help with rehabilitation.
I believe we have a bright future ahead of ourselves: AI will increasingly assist us in many areas to give us access to personalized, affordable, predictive and customizable training options.
Questions or Comments
What experience have you had with AI-powered training… and what excites you most about its future? Share below!





























{kind=link}